

Big Data
HDFS
- Hadoop Distributed File System. Part of the Apache Hadoop project, but the FS can be used as back-end storage by other project such as Spark and HBase.
- Originally designed as I/O system for Hadoop's MapReduce engine, thus good for large file stream access, not so good for small file random access.
- HDFS focus on extensive read and few writes. It actually does not have a random write mechanism.
- HDFS security is weak. It uses POSIX (UNIX) conventions, but intended to prevent accidental overwite. It is easy to circumvent securities. some admin may even set dfs.permissions to false and not deal with file permissions at all.
- config stored in /etc/hadoop, gazillion xml files in here :(
need to duplicate this config on all nodes of the hadoop cluster. - NameNode: stores metadata only (Think of MDS in Lustre).
defined in fs.default.name, eg: hdfs://dumbo:9000
This tends to be a single node and presents a SPOF. Cloudera provides an active/passive HA setup.
Actual storage location of the metadata is defined in dfs.name.dir, default to /tmp, - DataNode: store file data (block) (Think of OSS in Lustre).
Defined in dfs.data.dir, Hadoop default to /tmp.
Different nodes can use diff path. One possibility is each /dev/sdX be mounted as /hdfs/dataX (but would it not be better use RAID and have single /hdfs/data? who is better at stripping and distributing load? HDFS algorithm or RAID controller?)
- Web interface runs on NameNode. config in hadoop-site.xml :: dfs.http.address. eg http://dumbo:50070/
- Each DataNode has a basic file browser on dfs.datanode.http.address eg http://dumbo-data007:50075.
- Yahoo Implementation of Google's GFS and MapReduce.
HDFS usage
Ref: YDN Hadoop This guide likely written before hdfs split off from hadoop. Thus, the "hdfs" command was called "hadoop".hdfs dfs -ls # list user's HDFS BASE dir (/user/$USER) hdfs dfs -ls / # list files from root of HDFS hdfs dfs -mkdir /user/bofh # make user's home dir, special priv requeired. hdfs dfs -put foo bar # copy file/dir "foo" from unix to hdfs and name it bar # -put will copy file to ALL dataNodes. # -put will error if destination file "bar" already exist. # -put will recursive copy if "foo" is a directory. hdfs dfs -put foo # copy file foo from unix. Destination is HDFS BASE dir since not specified. ?? or not allowed ?? hdfs dfs -get bar baz # -get is to retrieve file/dir "bar" from HDFS to unix, saving it as "baz". # only -put and -get deal with file exchange b/w hdfs and unix # all other commands are manipulating files w/in hdfs hdfs dfs -setrep # set replication level hdfs dfs -help CMD # get help on command hdfs dfs -cat bar # like cat inside HDFS hdfs dfs -lsr # ls -r inside hdfs hdfs dfs -du path hdfs dfs -dus # du -s, ie display summary data hdfs dfs -mv src dest # move WITHIN hdfs hdfs dfs -cp src dest # copy WITHIN hdfs hdfs dfs -rm path # rm WITHIN hdfs. use -rmr for rm -r hdfs dfs -touchz path # z for zero hdfs dfs -test -e|z|d path # Exist, Zero legth, Directory hdfs dfs -stat FORMAT path # hdfs dfs -tail -f bar # tail [-f] bar (file inside HDFS) hdfs dfs -chmod -R 750 path hdfs dfs -chown -R OWNER path # chown, if no owner defined, change to me hdfs dfs -chgrp -R GRP path hdfs distcp -help # read up on distributed cp, it starts MapReduce task to lighten large copy hdfs dfsadmin -report hdfs dfsadmin -help hdfs fsck PATH OPTIONS # check health of hdfs
Apache Hadoop
- MapReduce engine, disk centric.
- Batch processing only. Think of HPC, but not using a queue manager to submit shell script, general unix commands job.
- Run specialized map-reduce program in a cluster (parallel) environment.
- Hadoop YARN: Hadoop's own scheduler to run jobs and resource management.
HBase
- Provides a NoSQL database access on top of Hadoop/HDFS. Modeled after Google BigTable
- Allow for efficient random read/write access, making it good for real-time data processing.
- Data stored in key/value columnar format.
- HBase is good when data is read and written using keys, and when records have varying number of fields so traditional SQL/Relational DB won't be a good fit.
- NoSQL also means it is not good at joins and other complex SQL queries.
- Adopters: Hulu, ...
Apache Hive
- Big Data Warehouse facility on top of Hadoop/HDFS.
- Provides HiveQL, a SQL-like way to read/write data.
- Can map HBase table to Hive and use its SQL feature.
- Can map HDFS file to Hive table and use HiveQL.
- Under the hood, Hive is converted into MapReduce. It saves a lot of tedious coding!
- Originally developed by Facebook.
- Commercial support: Hortonworks
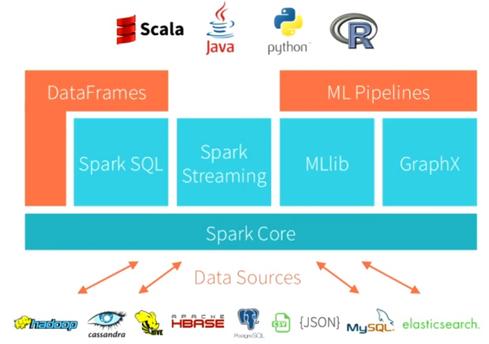
Apache Spark
- in-memory for "medium data" , much faster performance than disk-based Hadoop (which tends to want to write data back to disk for syncs of distributed processing.)
- long term storage can be stored in variety of "disk" based system, such as HDFS.
- Can be installed and run alongside Hive.
- Support MapReduce, but native model is RDD (resilient distributed dataset), which also allows for imperative programming.
- Provides a uniform access to data irrespective to its underlaying source (Hive, JSON, JDBC, etc)
For example, Spark can use Parquet, which is a columnar store touted for fast data access. Compare this to Vertica DB. - My Python page has an example code for submitting a spark job into a Cloudera YARN cluster.
-
Berkeley Data Analytics Stack (BDAS, or "Bad Ass"), the originator of Spark, has it implemented like this:
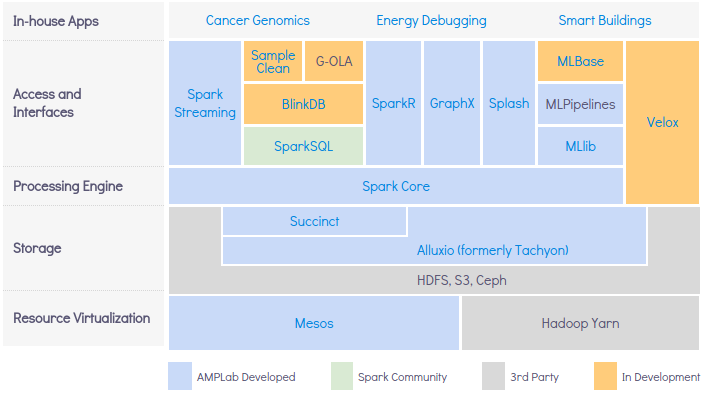
- Above the Spark Core, there are several access mechanism:
- Spark SQL: good for traditional Relational DB style queries
Spark SQL, DataFrames getting started. - Spark Streaming
- MLlib for machine learning
- Spark SQL: good for traditional Relational DB style queries
- Spark fit into a very diverse Big Data ecosystem. It can use a wide variety of input data source, even combining them to provide a single analytics.
- Promising use case scenaries as described by Information Week:
- Interesting deployment scenarios:
- Spark on Mesos
- Spark and Cassandra
- GPU Computing with Spark and Python
- Spark and Distributed Monte Carlo
- Spark inside a Docker container
- SparkSQL using Solr, Couchbase, Vertica DB as data source
spark troubleshooting
http://n0156.lr3:8080/ - spark master (scheduler, monitor worker) http://n0161.lr3:8081/ - worker process http://n0093.lr3:4040/jobs/ - overview of job process, one port per job spark://n0093.lr3:7077/ - spark protocol for spart-submit to send job to the master
Apache Kafka
- A Message queue for stream processing (use publish-subscribe model)
- Compare to AWS Kinesis? Aim for IoT?
Apache Storm
- Storm makes it easy to reliably process unbounded streams of data, doing for realtime processing what Hadoop did for batch processing. Storm is simple, can be used with any programming language
Cassandra
- high scale db.
- Non-Relational, Schema-Free, No-SQL
- Aggregate most data as they are written, instead of running MapReduce as post processing. (ref: http://blog.markedup.com/2013/02/cassandra-hive-and-hadoop-how-we-picked-our-analytics-stack/
- Adopters: ebay, ...
- eg of commercial player: DataStax
CouchDB, PouchDB, memcached, Couchbase
- Non relational, NoSQL, Schema-Free, document-oriented database for interactive application.
- Support peer-to-peer sync, where copies of a DB can go offline, get updates, and resync with rest of network copies when reconnect online.
- CouchDB written in the functional language Erlang!!
- Couchbase server is from the merging of CouchDB and memcached.
MongoDB
- NoSQL "huMONGOus DB"
- schema-free, store data as BSON (derivative of JSON).
- focus on unstructured documents.
- User pick a shard key, and DB is load balanced using horizontal partitioning.
- Provide a Grid File System with automatic load balancing (based on sharding above).
SciDB
- Database and code execution in the same cluster
- Need postgres eg v8.4
- /opt/scidb-1.0/etc/config.ini file list nodes in cluster. a given node can have more than 1 worker.
- http://www.paradigm4.com/try_scidb/
- paradigm4's SciDB: large, many dimension array. use hpc to process large data without learning MPI, MapReduce.
su - scidb
scidb.py init all mycluster
scidb.py startall mycluster
scidb.py status mycluster
iquery -aq "list('arrays')" # list avail arrays. [] means empty list
iquery -q
iquery -q 'create array X < x: uint64 > [ i=1:10001,1000,0, j=1:10001,1000,0]' # creates a test array
Docker
- container for apps.
- much thinner than a whole VM.
- provides a consistent env for app to run, irrespective of underlaying OS.
- Think of yum for a mesos cluster
- see docker.html for more info.
Apache Aurora
- support phased rollout
- support complex rollout, at the expense of hard to use.
- so does not support docker?
Node.JS
- App server, think of Tomcat, JBoss.
- Support JavaScript for Map Reduce queries. (eg, as opposed to using C#)
- npm is the "yum" for node.js
Parallel Environment
- See mpi.html (include OpenMP, ScaleMP, PVM).
Apache Mesos
- Cluster manager. Scheduler + Provider (client) model. In addition to a typical HPC queue manager/scheduler, Mesos clients are setup as resource provider of resources, allowing for granular resource provisioning. Client run daemon to advertise what's available, with memory, cpu and whatever portion that it wants to advertise for scheduler to dispatch job to it.
- It is like doing time sharing of mainframe for cluster. Allows multiple user to run (eg Hardoop) jobs at the same time. Utilize Linux Container (like lightweight Virtual Machine) to create compartmentalization between users, and give each user a share of the hardware. ref: https://www.youtube.com/watch?v=gVGZHzRjvo0
- Compare to secretive Google Omega scheduler
- http://mesos.apache.org/
- http://www.meetup.com/Bay-Area-Mesos-User-Group/
- mesos can bootstrap various types of cluster, such as hadoop, spark. and resize each of these cluster dynamically.
- traditional cluster manager queue job, make user wait. no feedback. when job run, may fail, and a little fix may have to wait long ago. some maybe contrain specification fix...
- traditional cluster hard to create complex specification, eg version of GPU needed for diff app.
- Marathon on top of Mesos... provide PaaS.
- Chronos... run cron job, also support dependecies. used by Tweeter... so closer to SGE jobs?
- Support Hardoop, MPI, Torque frameworks (ie as "apps")mesos slide deck, 2011, amplab
- Mesos originally came from Berkeley's AMPLab. It graduated and was donated to Apache to mature as a community project.
AirBnB Chronos (Mesos Framework)
- http://nerds.airbnb.com/introducing-chronos/
- Cron replacement, for Mesos. run any ba/sh scripts.
- But nature is to run job at certain time, so does not pack jobs to run like SGE queue manager.
- supports dependency, but multiple job scheduled to run at same time, then depends on mesos to deploy resource to run job? potentially run jobs in parallel and slow down everyone?
CfnCluster
cfncluster is a framework that deploys and maintains HPC clusters on AWS. It is reasonably agnostic to what the cluster is for and can easily be extended to support different frameworks. The CLI is stateless, everything is done using CloudFormation or resources within AWShttp://cfncluster.readthedocs.org/en/latest/getting_started.html
MIT StarCluster
Also a way to deploy and maintains HPC in AWS. but cfncluster seems to be where the action is now. see aws.html for sample POC setup session.Terminology
RDD, DataFrame
- RDD = Resiliet Distributed Dataset. This is the basic data abstraction used by Spark to represent data
Operation on RDD revolves around MapReduce, thus needing many lambda functions in its coding. - DataFrame, often abreviated DF, is a new, higher level construct.
DF codes are closer to javaScript. It is based in Functional approach, but the code does not require much lambda declarations to map out the deail on how to iterate thru the dataset.
- RDDs are the new bytecode of apache spark highlight a very cleaver example. The DF code shown is:
data.groupBy("dept").avg("age")
shard
- Shard is partitioning db into horizontal slices. eg. using 2 letter symbols as shard keys to create 50 partitions, 1 for each state.
- Natural way of scaling a large db across many servers. but may not have natural shard key.
- Tend to create a single point of failure. HA, failover, backup all get more complications.
- Adopted by quite a number of DB: MongoDB, HBase, MySQL Cluster.
Apache Parquet
- Parquet provides a column-based storage for the Hadoop env.
- It provides per column compression, with special attention to complex and nested data structure
- For data that repeats inside the column, the compression and encoding puts similar data together and reduces disk I/O.
- Ref: Parquet doc
- Ref: https://spark.apache.org/docs/latest/sql-programming-guide.html#parquet-files
scala
- Provide functional programming, modern constructs like closures, parametric types and virtual type members.
- Compatible with java: classes b/w scala and java can call each other w/o glue code. Thus, Scala does not force functional programming, but allows OOP as well.
- (Java 8 included annonymous (lambda) functions)
- Spark, Kafka written using Scala.
Links
- Hadoop toolbox, gives a brief description of what Hadoop tool do what. Also covers Hive, Pig, Sqoop, Oozie, etc.
Search within the PSG pages:
Copyright info about this work
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike2.5 License.
Pocket Sys Admin Survival Guide: for content that I wrote, (CC)
some rights reserved.
2005,2012 Tin Ho [ tin6150 (at) gmail.com ]
Some contents are "cached" here for easy reference. Sources include man pages,
vendor documents, online references, discussion groups, etc. Copyright of those
are obviously those of the vendor and original authors. I am merely caching them here for quick reference and avoid broken URL problems.
Where is PSG hosted these days?
tiny.cc/BIGD
http://tin6150.github.io/psg/psg2.html This new home page at github
http://tiny.cc/tin6150/ New home in 2011.06.
http://tin6150.s3-website-us-west-1.amazonaws.com/psg.html (coming soon)
ftp://sn.is-a-geek.com/psg/psg.html My home "server". Up sporadically.
http://tin6150.github.io/psg/psg.html
http://www.fiu.edu/~tho01/psg/psg.html (no longer updated as of 2007-05)
http://tin6150.github.io/psg/psg2.html This new home page at github
http://tiny.cc/tin6150/ New home in 2011.06.
http://tin6150.s3-website-us-west-1.amazonaws.com/psg.html (coming soon)
ftp://sn.is-a-geek.com/psg/psg.html My home "server". Up sporadically.
http://tin6150.github.io/psg/psg.html
http://www.fiu.edu/~tho01/psg/psg.html (no longer updated as of 2007-05)

