[Contents] [Prev] [Next] [End]
This chapter introduces important concepts related to the design and operation of LSF.
This section contains definitions of terms used in this guide.
Throughout this guide, LSF refers to the LSF suite of products, which contains the following components:
LSF Base provides the basic load-sharing services across a heterogeneous network of computers. It is the base software upon which all other LSF functional components are built. It provides services such as resource information, host selection, placement advice, transparent remote execution and remote file operation, etc.
LSF Base includes Load Information Manager (LIM), Remote Execution Server (RES), the LSF Base API, lstools that allow the use of the LSF Base system to run simple load-sharing applications, lstcsh, and lsmake.
An LSF Base cluster contains a network of computers running LIM, RES and lstools. The cluster is defined by LSF cluster configuration files, which are read by LIM. LIM then provides the cluster configuration information, together with all other dynamic information to the rest of the LSF Base system, as well as to other LSF functional components.
LSF Base system API allows users to write their own load-sharing applications on top of the LSF Base system.
LSF Batch is a distributed batch queuing system built on top of the LSF Base. The services provided by LSF Batch are extensions to the LSF Base system services. LSF Batch makes a computer network a network batch computer. It has all the features of a mainframe batch job processing system while doing load balancing and policy-driven resource allocation control.
LSF Batch relies on services provided by the LSF Base system. It makes use of the resource and load information from the LIM to do load balancing. LSF Batch also uses the cluster configuration information from LIM and follows the master election service provided by LIM. LSF Batch uses RES for interactive batch job execution and uses the remote file operation service provided by RES for file transfer. LSF Batch includes a Master Batch Daemon (mbatchd) running on the master host and a slave Batch Daemon (sbatchd) running on each batch server host.
LSF Batch has its own configuration files in addition to the use of the cluster configuration from the LSF Base system.
LSF JobScheduler is a network production job scheduling system that automates the mission-critical activities of a MIS organization. It provides reliable job scheduling on a heterogeneous network of computers with centralized control. LSF JobScheduler reacts to calendars and events to schedule jobs at the correct time on the correct machines.
Like LSF Batch, LSF JobScheduler is built on top of the LSF Base system. It relies on LSF Base system in resource matching, job placement, cluster configuration, and distributed file operation. LSF JobScheduler support calendars, file events, and user defined events in scheduling production jobs.
LSF JobScheduler also includes most of the functionality of LSF Batch in load balancing and job queuing. In fact LSF JobScheduler shares most of the binaries, for example, mbatchd, sbatchd, and job manipulation commands.
Note
In the reminder of this guide, all descriptions of LSF Batch apply to LSF JobScheduler unless explicitly stated otherwise.
LSF MultiCluster extends the capabilities of the LSF system by sharing the resources of an organization across multiple cooperating clusters of computers. Load sharing happens not only within the clusters but also among them. Resource ownership and autonomy is enforced, non-shared user accounts and file systems are supported, and communication limitations among the clusters are also considered in job scheduling.
This document uses the terms job, task, and command to refer to one or more UNIX processes invoked together to perform some action. The terms are interchangeable, though task is more often used to refer to interactive commands and job is more often used for commands run using the batch system.
Each command may be a single UNIX process, or it may be a group of cooperating processes in a UNIX process group. LSF creates a new process group for each command it runs, and the job control mechanisms act on all processes in the process group.
This document uses the terms host, machine, and computer to refer to a single computer, which may have more than one processor. An informal definition is: if it runs a single copy of the operating system and has a unique Internet (IP) address, it is one computer. More formally, LSF treats each UNIX process queue as a separate machine. A multiprocessor computer with a single process queue is considered a single machine, while a box full of processors that each have their own process queue is treated as a group of separate machines.
A cluster is a group of hosts that provide shared computing resources. Hosts can be grouped into clusters in a number of ways. A cluster could contain:
If you have hosts of more than one type, it is often convenient to group them together in the same cluster. LSF allows you to use these hosts transparently, so applications that run on only one host type are available to the entire cluster.
When LSF runs a remote command, two hosts are involved. The host where the remote execution is initiated is the local host. The host where the command is executed is the remote host. For example, in this sequence:
hostA% lsrun -v hostname <<Execute hostname on remote host hostD>> hostD hostA%
the local host is hostA, and the remote host is hostD. Note that it is possible for the local and remote hosts to be the same.
When LSF Batch runs a job, three hosts are involved. The host from which the job is submitted is the submission host. The job information is sent to the master host, which is the host where the master LIM and mbatchd are running. The job is run on the execution host. It is possible for more than one of these to be the same host.
The master host is displayed by the lsid command:
% lsid LSF 3.0, Dec 10, 1996 Copyright 1992-1996 Platform Computing Corp. My cluster name is test_cluster My master name is hostA
The following example shows the submission and execution hosts for a batch job:
hostD% bsub sleep 60 Job <1502> is submitted to default queue <normal> hostD% bjobs 1502 JOBID USER STAT QUEUE FROM_HOST EXEC_HOST JOB_NAME SUBMIT_TIME 1502 user2 RUN normal hostD hostB sleep 60 Nov 22 14:03
The master host is hostA, as shown by the lsid command. The submission host is hostD, and the execution host is hostB.
LSF has a number of features to support fault tolerance. LSF can tolerate the failure of any host or group of hosts in the cluster.
The LSF master host is chosen dynamically. If the current master host becomes unavailable, another host takes over automatically. The master host selection is based on the order in which hosts are listed in the lsf.cluster.cluster file. If the first host in the file is available, that host acts as the master. If the first host is unavailable, the second host takes over, and so on. LSF may be unavailable for a few minutes while hosts wait to be contacted by the new master.
If the cluster is partitioned by a network failure, a master LIM takes over on each side of the partition. Interactive load-sharing remains available, as long as each host still has access to the LSF executables.
Fault tolerance in LSF Batch depends on the event log file, lsb.events. Every event in the system is logged in this file, including all job submissions and job and host status changes. If the master host becomes unavailable, a new master is chosen by the LIMs. The slave batch daemon sbatchd on the new master starts a new master batch daemon mbatchd. The new mbatchd reads the lsb.events file to recover the state of the system.
If the network is partitioned, only one of the partitions can access the lsb.events log, so batch services are only available on one side of the partition. A lock file is used to guarantee that only one mbatchd is running in the cluster.
Running jobs are managed by the sbatchd on each batch server host. When the new mbatchd starts up it polls the sbatchd daemons on each host and finds the current status of its jobs. If the sbatchd fails but the host is still running, jobs running on the host are not lost. When the sbatchd is restarted it regains control of all jobs running on the host.
If an LSF server host fails, jobs running on that host are lost. No other jobs are affected. LSF Batch jobs can be submitted so that they are automatically rerun from the beginning or restarted from a checkpoint on another host if they are lost because of a host failure.
If all of the hosts in a cluster go down, all running jobs are lost. When a host comes back up and takes over as master, it reads the lsb.events file to get the state of all batch jobs. Jobs that were running when the systems went down are assumed to have exited, and email is sent to the submitting user. Pending jobs remain in their queues, and are scheduled as hosts become available.
LSF is designed for networks where all hosts have shared file systems, and files have the same names on all hosts. LSF supports the Network File System (NFS), the Andrew File System (AFS), and DCE's Distributed File System (DFS). NFS file systems can be mounted permanently or on demand using automount.
LSF includes support for copying user data to the execution host before running a batch job, and for copying results back after the job executes. In networks where the file systems are not shared, this can be used to give remote jobs access to local data.
For more information about running LSF on networks where no shared file space is available, see 'Using LSF Without Shared File Systems'.
To provide transparent remote execution, LSF commands determine the user's current working directory and use that directory on the remote host. For example, if the command cc file.c is executed remotely, cc only finds the correct file.c if the remote command runs in the same directory.
The LSF Batch and LSF JobScheduler automatically create a .lsbatch subdirectory in the user's home directory on the execution host. This directory is used to store temporary input and output files for jobs.
Search paths for executables (the PATH environment variable) are passed to the remote execution host unchanged. In mixed clusters, LSF works best when the user binary directories (/usr/bin, /usr/local/bin, etc.) have the same path names on different host types. This makes the PATH variable valid on all hosts.
If your user binaries are NFS mounted, you can mount different binary directories under the same path name. Another way of handling multiple host types is to place all binaries in a shared file system under /usr/local/mnt (or some similar name), and then make a symbolic link from /usr/local/bin to /usr/local/mnt/bin/type for the correct host type on each machine.
LSF configuration files are normally in a shared directory. This makes administration easier. There is little performance penalty for this, because the configuration files are not read often.
Some networks do not share files between hosts. LSF can still be used on these networks, with reduced fault tolerance.
You must choose one host to act as the LSF Batch master host. The LSF Batch configuration files and working directories must be installed on this host, and the master host must be listed first in the lsf.cluster.cluster file.
To install on a cluster without shared file systems, follow the complete installation procedure on every host to install all the binaries, manual pages, and configuration files. After you have installed LSF on every host, you must update the configuration files on all hosts so that they contain the complete cluster configuration. The configuration files must be the same on all hosts.
If the master host is unavailable, users cannot submit batch jobs or check job status. Running jobs continue to run, but no new jobs are started. When the master host becomes available again, LSF Batch service is resumed.
Some fault tolerance can be introduced by choosing more than one host as possible master hosts, and using NFS to mount the LSF Batch working directory on only these hosts. All the possible master hosts must be listed first in the lsf.cluster.cluster file. As long as one of these hosts is available, LSF Batch continues to operate.
To run applications quickly and correctly, LSF needs to know their resource requirements. Resource requirements are strings that contain resource names and operators. There are several types of resources. Load indices measure dynamic resource availability such as a host's CPU load or available swap space. Static resources represent unchanging information such as the number of CPUs a host has, the host type, and the maximum available swap space.
Resource names may be any string of characters, excluding the characters reserved as operators. The lsinfo command lists the resources available in your cluster.
For a complete description of the load indices supported by LSF and how they are used, see the 'Resources' chapter of the LSF User's Guide, or the 'Advanced Features' chapter of the LSF JobScheduler User's Guide.
LSF needs to match host names with the corresponding Internet host addresses. Host names and addresses can be looked up in the /etc/hosts file, Sun's Network Information System/Yellow Pages (NIS or YP), or the Internet Domain Name Service (DNS). DNS is also known as the Berkeley Internet Name Domain (BIND) or named, which is the name of the BIND daemon. Each UNIX host is configured to use one or more of these mechanisms.
Each host has one or more network addresses; usually one for each network to which the host is directly connected. Each host can also have more than one name. The first name configured for each address is called the official name; other names for the same host are called aliases.
LSF uses the configured host naming system on each host to look up the official host name for any alias or host address. This means that you can use aliases as input to LSF, but LSF always displays the official name.
On Digital Unix systems, the /etc/svc.conf file controls which name service is used. On Solaris systems, the /etc/nsswitch.conf file controls the name service. On other hosts, the following rules apply:
The manual pages for the gethostbyname function, the ypbind and named daemons, the resolver functions, and the hosts, svc.conf, nsswitch.conf, and resolv.conf files explain host name lookups in more detail.
Hosts which have more than one network interface usually have one Internet address for each interface. Such hosts are called multi-homed hosts. LSF identifies hosts by name, so it needs to match every one of these addresses with a single host name. To do this, the host name information must be configured so that all of the Internet addresses for a host resolve to the same name.
Some system manufacturers recommend that each network interface, and therefore, each Internet address, be assigned a different host name. Each interface can then be directly accessed by name. This setup is often used to make sure NFS requests go to the nearest network interface on the file server, rather than going through a router to some other interface. Configuring this way can confuse LSF, because there is no way to determine that the two different names (or addresses) mean the same host. LSF provides a workaround for this problem; see 'The hosts File'.
All host naming systems can be configured so that host address lookups always return the same name, while still allowing access to network interfaces by different names. Each host has an official name and a number of aliases, which are other names for the same host. By configuring all interfaces with the same official name but different aliases, you can refer to each interface by a different alias name while still providing a single official name for the host.
Here are examples of /etc/hosts entries. The first example is for a host with two interfaces, where the host does not have a unique official name.
# Address Official name Aliases # Interface on network A AA.AA.AA.AA host-AA.domain host.domain host-AA host # Interface on network B BB.BB.BB.BB host-BB.domain host-BB host
Looking up the address AA.AA.AA.AA finds the official name host-AA.domain. Looking up address BB.BB.BB.BB finds the name host-BB.domain. No information connects the two names, so there is no way for LSF to determine that both names, and both addresses, refer to the same host.
Here is the same example, with both addresses configured for the same official name:
# Address Official name Aliases # Interface on network A AA.AA.AA.AA host.domain host-AA.domain host-AA host # Interface on network B BB.BB.BB.BB host.domain host-BB.domain host-BB host
With this configuration, looking up either address returns host.domain as the official name for the host. LSF (and all other applications) can determine that all the addresses and host names refer to the same host. Individual interfaces can still be specified by using the host-AA and host-BB aliases.
Sun's NIS uses the /etc/hosts file on the NIS master host as input, so the format for NIS entries is the same as for the /etc/hosts file.
The configuration format is different for DNS. The same result can be produced by configuring two address (A) records for each Internet address. Following the previous example:
# name class type address host.domain IN A AA.AA.AA.AA host.domain IN A BB.BB.BB.BB host-AA.domain IN A AA.AA.AA.AA host-BB.domain IN A BB.BB.BB.BB
Looking up the official host name can return either address. Looking up the interface-specific names returns the correct address for each interface.
Address-to-name lookups in DNS are handled using PTR records. The PTR records for both addresses should be configured to return the official name:
# address class type name AA.AA.AA.AA.in-addr.arpa IN PTR host.domain BB.BB.BB.BB.in-addr.arpa IN PTR host.domain
If it is not possible to change the system host name database, you can create a hosts file local to the LSF system. This file only needs to have entries for multi-homed hosts. Host names and addresses not found in this file are looked up in the standard name system on your host. See 'The hosts File' for more information on the LSF hosts file.
There are two aspects to controlling access to remote execution. The first requirement is to authenticate the user. When a user executes a remote command, the command must be run with that user's permission. The LSF daemons need to know which user is requesting the remote execution. The second requirement is to check access controls on the remote host. The user must be authorized to execute commands remotely on the host.
LSF supports user authentication using privileged ports, authentication using the RFC 931 or RFC 1413 identification protocols, and site-specific external authentication, such as Kerberos and DCE.
The default method is to use privileged ports. To use privileged ports, some of the LSF utilities must be installed with root as the owner of the file and with the setuid bit set.
If a load-sharing program is owned by root and has the setuid bit set, the LSF API functions use a privileged port to communicate with LSF servers, and the servers accept the user ID supplied by the caller. This is the same user authentication mechanism as used by rlogin and rsh.
When a setuid application calls the LSLIB initialization routine, a number of privileged ports are allocated for remote connections to LSF servers. The effective user ID then reverts to the real user ID. Therefore, the number of remote connections is limited. Note that a load-sharing application reuses the connection to the RES for all remote task executions on that host, so the number of privileged ports is only a limitation on the number of remote hosts that can be used by a single application, not on the number of remote tasks. Programs using LSLIB can specify the number of privileged ports to be created at initialization time.
The RFC 1413 and RFC 931 protocols use an identification daemon running on each client host. Using an identification daemon incurs more overhead, but removes the need for LSF applications to allocate privileged ports. All LSF commands except lsadmin can be run without setuid permission if an identification daemon is used.
You should use identification daemons if your site cannot install programs owned by root with the setuid bit set, or if you have software developers creating new load-sharing applications in C using LSLIB.
An implementation of RFC 931 or RFC 1413 such as pidentd or authd, may be obtained from the public domain1.. RFC 1413 is a more recent standard than RFC 931. LSF is compatible with either.
You can configure your own user authentication scheme using the eauth mechanism of LSF. If external authentication is used, an executable called eauth must be written and installed in LSF_SERVERDIR.
When an LSF client program is invoked (for example, lsrun), the client program automatically executes eauth -c hostname to get the external authentication data. hostname is the name of the host running the LSF daemon (for example, RES). The external user authentication data can be passed to LSF via eauth's standard output.
When the LSF daemon receives the request, it executes eauth -s under the primary LSF administrator user ID. The parameter, LSF_EAUTH_USER, must be configured in the /etc/lsf.sudoers file if your site needs to run authentication under another user ID (see 'The lsf.sudoers File' for details). eauth -s is executed to process the user authentication data. The data is passed to eauth -s via its standard input. The standard input stream has the following format:
uid gid username client_addr client_port user_auth_data_len user_auth_data
The LSF daemon expects eauth -s to write 1 to its standard output if authentication succeeds, or 0 if authentication fails.
The same eauth -s process can service multiple authentication requests; if the process terminates, the LSF daemon will re-invoke eauth -s on the next authentication request.
Example uses of external authentication include support for Kerberos 4 and DCE client authentication using the GSSAPI. These examples can be found in the examples/krb and examples/dce directories in the standard LSF distribution. Installation instructions are found in the README file in these directories.
All authentication methods supported by LSF depend on the security of the root account on all hosts in the cluster. If a user can get access to the root account, they can subvert any of the authentication methods. There are no known security holes that allow a non-root user to execute programs with another user's permission.
Some people have particular concerns about security schemes involving RFC 1413 identification daemons. When a request is coming from an unknown host, there is no way to know whether the identification daemon on that host is correctly identifying the originating user.
LSF only accepts job execution requests that originate from hosts within the LSF cluster, so the identification daemon can be trusted. The identification protocol uses a port in the UNIX privileged port range, so it is not possible for an ordinary user to start a hacked identification daemon on an LSF host.
LSF uses the LSF_AUTH parameter in the lsf.conf file to determine the type of authentication to use.
If an LSF application is not setuid to root, library functions use a non-privileged port. If the LSF_AUTH flag is not set in the /etc/lsf.conf file, the connection is rejected. If LSF_AUTH is defined to be ident, the RES on the remote host, or the mbatchd in the case of a bsub command, contacts the identification daemon on the local host to verify the user ID. The identification daemon looks directly into the kernel to make sure the network port number being used is attached to a program being run by the specified user.
LSF allows both the setuid and authentication daemon methods to be in effect simultaneously. If the effective user ID of a load-sharing application is root, then a privileged port number is used in contacting the RES. RES always accepts requests from a privileged port on a known host even if LSF_AUTH is defined to be ident. If the effective user ID of the application is not root, and the LSF_AUTH parameter is defined to be ident, then a normal port number is used and RES tries to contact the identification daemon to verify the user's identity.
External user authentication is used if LSF_AUTH is defined to be eauth. In this case, LSF will run the external executable eauth in the LSF_SERVERDIR directory to do the authentication.
The error message "User permission denied" is displayed by lsrun, bsub, and other LSF commands if LSF cannot verify the user's identity. This may be because the LSF applications are not installed setuid, the NFS directory is mounted with the nosuid option, the identification daemon is not available on the local or submitting host, or the external authentication failed.
If you change the authentication type while the LSF daemons are running, you will need to run the command lsfdaemons start on each of the LSF server hosts so that the daemons will use the new authentication method.
When a batch job or a remote execution request is received, LSF first determines the user's identity. Once the user's identity is known, LSF decides whether that user has permission to execute remote jobs.
LSF normally allows remote execution by all users except root, from all hosts in the cluster. Users must have valid accounts on all hosts. This allows any user to run a job with their own permission on any host in the cluster. Remote execution requests and batch job submissions are rejected if they come from a host not in the LSF cluster.
If the LSF_USE_HOSTEQUIV parameter is set in the lsf.conf file, LSF uses the same remote execution access control mechanism as the rsh command. When a job is run on a remote host, the user name and originating host are checked using the ruserok function on the remote host. This function checks in the /etc/hosts.equiv file and the user's $HOME/.rhosts file to decide if the user has permission to execute jobs.
The name of the local host should be included in this list. RES calls ruserok for connections from the local host. mbatchd calls ruserok on the master host, so every LSF Batch user must have a valid account and remote execution permission on the master host.
The disadvantage of using the /etc/hosts.equiv and $HOME/.rhosts files is that these files also grant permission to use the rlogin and rsh commands without giving a password. Such access is restricted by security policies at some sites.
See the hosts.equiv(5) and ruserok(3) manual pages for details on the format of the files and the access checks performed.
The error message "User permission denied" is displayed by lsrun, bsub, and other LSF commands if you configure LSF to use ruserok and the client host is not found in either the /etc/hosts.equiv or the $HOME/.rhosts file on the master or remote host.
A site can configure an external executable to perform additional user authorization. By defining LSF_AUTH to be eauth, the LSF daemon will invoke eauth -s when it receives a request that needs authentication and authorization. As an example, this eauth can check if the client user is on a list of authorized users.
By default LSF assumes uniform user accounts throughout the cluster. This means that job will be executed on any host with exactly the same user ID and user login name.
LSF Batch has a mechanism to allow user account mapping across dissimilar name spaces. Account mapping can be done at the individual user level. Individual users of the LSF cluster can set up their own account mapping by setting up a .lsfhosts file in their home directories. See LSF User's Guide or LSF JobScheduler User's Guide for details of user level account mapping.
A job starter is an operation executed before the user's real job. This is useful to allow site or individual users to customize the execution environment before running the job. For example, by defining a job starter as "ksh -c", your job will run under the ksh environment.
If you want to use a job starter to run jobs using RES, you can define an environment variable LSF_JOB_STARTER. When this environment variable is defined, RES starts the job by running '$LSF_JOB_STARTER command'. See LSF User's Guide for more information about the use of a job starter with RES.
For LSF Batch jobs, job starters are defined at the queue level. In this case, the environment variable LSF_JOB_STARTER is ignored. See 'Using A Job Starter' for more details.
LSF Base system provides a very basic level of services that allow you to do load-sharing and distributed processing. This is implemented via the LSF Base system services. Many utilities of the LSF Base system uses the basic services for placement decision, host selection, and remote execution.
LIM provides convenient services that help job placement, host selection, and load information that are essential to the scheduling of jobs. lsrun, lsmake, and lsgrun, for example, use the LIM's placement advice to run jobs on the least loaded yet most powerful hosts. When LIM gives placement advice, it takes into consideration many factors, such as current load information, job's resource requirements and configured policies in the LIM cluster configuration file.
RES provides transparent and efficient remote execution and remote file operation services so that jobs can be easily shipped to anywhere in the network once a placement decision has been made. Files can be accessed easily from anywhere in the network using remote file operation services.
The LSF Base provides sufficient services to many simple load-sharing applications and utilities, as exemplified by lstools, lsmake, and lstcsh. If sophisticated job scheduling and resource allocation policies are necessary, more complex scheduling has to be built on top of the LSF Base such as LSF Batch. Since the placement service from LIM is just advice, LSF Batch makes its own placement decision based on advice from LIM as well as further policies that the site configures.
Time windows are an important concept in LSF. Time windows are a useful means to control resource access such that you can disable access to some resources during certain times. A time window is the basic building block for configuring dispatch windows and run windows.
A time window is specified by two time values separated by '-'. Each time value is specified by up to three fields:
[day:]hour[:min]
If only one field exists, it is assumed to be hour; if two fields exist, they are assumed to be hour:min. Days are numbered from 0 (Sunday) to 6 (Saturday). Hours are numbered from 0 to 23, and minutes from 0 to 59.
In a time window time1-time2, if neither time1 nor time2 specifies a day, the time window applies to every day of the week. If time1 is greater than time2, the time window applies from time1 of each day until time2 of the following day.
If either time1 or time2 specifies a day, both must specify a day. If time1 is on a later day of the week than time2, or is a later time on the same day, then the time window applies from time1 of each week until time2 of the following week.
A dispatch or run window is specified as a series of time windows. When a dispatch or run window specification includes more than one time window, the window is open if any of the time windows is open. The following example specifies that the host is available only during weekends (Friday evening at 19:00 until Monday morning at 08:30) and during nights (20:00 to 08:30 every day).
5:19:00-1:8:30 20:00-8:30
LSF Batch provides a rich collection of mechanisms for controlling the sharing of resources by jobs. Most sites do not use all of them; a few would provide enough control. However, it is important that you be aware of all of them to understand how LSF Batch works and to choose suitable controls for your site. More discussions of job scheduling policies are given in 'Tuning LSF Batch'.
When a job is placed on an LSF Batch queue, many factors control when and where the job starts to run:
When LSF Batch is trying to place a job, it obtains current load information for all hosts from LIM. The load levels on each host are compared to the scheduling thresholds configured for that host in the Host section of the lsb.hosts file, as well as the per-queue scheduling thresholds configured in the lsb.queues file. If any load index exceeds either its per-queue or its per-host scheduling threshold, no new job is started on that host. When a job is running, LSF Batch periodically checks the load level on the execution host. If any load index is beyond either its per-host or its per-queue suspending conditions, the lowest priority batch job on that host is suspended.
LSF Batch supports both batch jobs and interactive jobs. So by configuring appropriate resource allocation policies, all workload in your cluster can be managed by LSF Batch.
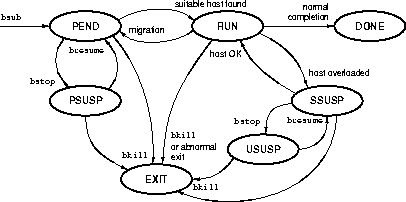
An LSF Batch job goes through a series of state transitions until it eventually completes its task, fails or is terminated. The possible states of a job during its life cycle are shown in Figure 4.
Many jobs enter only three states:
A job remains pending until all conditions for its execution are met. Some of the conditions are:
The bjobs -lp command displays the names of hosts that cannot accept a job at the moment together with the reasons the job cannot be accepted.
A job may terminate abnormally for various reasons. Job termination may happen from any state. An abnormally terminated job goes into EXIT state. The situations where a job terminates abnormally include:
Jobs may also be suspended at any time. A job can be suspended by its owner, by the LSF administrator, by the root user (superuser), or by the LSF Batch system. There are three different states for suspended jobs:
After a job has been dispatched and started on a host, it can be suspended by LSF Batch. If the load on the execution host or hosts becomes too high, batch jobs could be interfering among themselves or could be interfering with interactive jobs. In either case, some jobs should be suspended to maximize host performance or to guarantee interactive response time.
LSF Batch suspends jobs according to the priority of the job's queue. When a host is busy, LSF Batch suspends lower priority jobs first unless the scheduling policy associated with the job dictates otherwise. Jobs are also suspended by the system if the job queue has a run window and the current time goes outside the run window.
The bjobs -s command displays the reason why a job was suspended.
A system suspended job can later be resumed by LSF Batch if the load condition on the execution host (s) falls low enough or when the closed run window of the queue opens again.
Each time LSF Batch attempts to dispatch a job, it checks to see which hosts are eligible to run the job. A number of conditions determine whether a host is eligible:
A host is only eligible to run a job if all the conditions are met. If a batch job is queued and there is an eligible host for that job, the batch job is started on that host. If more than one host is eligible, the job is started on the best host based on the job's and the queue's resource requirements.
Each queue may be configured with a list of time periods, called dispatch windows, during which jobs in the queue can be dispatched. Jobs submitted to a queue are dispatched only when a queue dispatch window is open. Jobs may be submitted to a queue at any time; if the queue dispatch windows are closed, the jobs remain pending in the queue until a dispatch window opens. If no queue dispatch window is configured, the default is always open. Queue dispatch windows are displayed by the bqueues -l command.
Each host can also have dispatch windows. A host is not eligible to accept jobs when its dispatch windows are closed. Each batch job is dispatched from a specific queue, so a host is eligible to run a batch job if it is eligible for jobs from the queue, its dispatch windows are open, and it has the LSF resources required by the job. If no host dispatch window is configured, the default is always open. Host dispatch windows are displayed by the bhosts -l command.
Dispatch windows only control dispatching. Once a job has been dispatched to a host, it is unaffected by the status of dispatch windows.
Each queue may be configured with a list of time periods, called run windows, during which jobs from the queue can run. Jobs submitted to a queue only run when a queue run window is open. Jobs may be submitted to a queue at any time; if the queue run windows are closed, the jobs remain pending in the queue until a queue run window opens. When all of a queue's run windows close, any jobs dispatched from the queue are suspended until the queue's next run window opens. If no queue run window is configured, the default is always open. Queue run windows are displayed by the bqueues -l command.
Run windows also affect dispatching. No jobs are dispatched from a queue while its run windows are closed.
Each job may specify resource requirements. The resource requirements restrict which hosts the job can run on. For example, if your cluster contains three hosts with the spice resource and you give the argument -R spice to the bsub command, your job can only run on one of those three hosts. The lshosts command displays the resources available on each host. Each job may also specify an explicit list of eligible hosts, using the -m option to bsub. The bjobs -l command displays this list for each job.
Each queue may define resource requirements that will be applied to all the jobs in the queue. The queue-level resource requirements can also serve as job scheduling conditions shared by all jobs in the queue.
Each queue can be configured with a list of eligible hosts. For example, a queue for running programs on shared memory multiprocessors can be configured so that only the multiprocessor hosts are eligible. The eligible hosts for a queue are displayed by the bqueues -l command.
A host is available if the values of the load indices (such as r1m, pg, mem) of the host are within the configured scheduling thresholds. There are two sets of scheduling thresholds: host and queue. If any load index on the host exceeds the corresponding host threshold or queue threshold, the host is not eligible to run any job. The bhosts -l command displays the host thresholds. The bqueues -l command displays the queue thresholds.
Resource requirements at the queue level can also be used to specify scheduling conditions (for example, r1m<0.4 && pg<3).
Each LSF Batch queue has a priority number. LSF Batch tries to start jobs from the highest priority queue first. Within each queue, by default jobs are dispatched in first-come, first-served order. If a fairshare scheduling policy has been specified for the queue or if host partitions have been configured, jobs are dispatched in accordance with these policies. (See 'Fairshare in Queues' and 'Fairshare in Host Partitions'.)
The bjobs command shows the order in which jobs in a queue will actually be dispatched for the FCFS policy. This order may be changed by the btop and bbot commands (see 'Moving Jobs --- bswitch, btop, and bbot').
Jobs may be dispatched out of turn if pre-execution conditions are not met, specific hosts or resources are busy or unavailable, or a user has reached the user job slot limit. (See 'Host Load Levels', 'User Job Slot Limits', and 'Queue-Level Pre-/Post-Execution Commands'.)
Jobs are dispatched at 60 second intervals (the interval is configured by the MBD_SLEEP_TIME parameter in the lsb.params file). In each dispatching turn, LSF Batch tries to start as many jobs as possible.
To prevent overloading any host, LSF Batch waits for a configured number of dispatching intervals before sending another job to the same host. The waiting time is configured by the JOB_ACCEPT_INTERVAL parameter in the lsb.params file; the default is one dispatch interval. If JOB_ACCEPT_INTERVAL is set to zero, more than one job may be started on a host in the same dispatch turn.
The algorithm for starting jobs is:
For each queue, from highest to lowest priority
{
For each job in the queue, from first to last
{
If any host is eligible to run this job, start the job on the best
eligible host, and mark that host ineligible to run any other
job until JOB_ACCEPT_INTERVAL dispatch turns have passed
}
}
A higher priority or earlier batch job is only bypassed if no hosts are available that meet the requirements of the job. If a host is available but is not eligible to run a particular job, LSF Batch looks for a later job to start on that host. The first job found for which that host is eligible is started.
Job slot is the basic unit of processor allocation in LSF Batch. A sequential job uses one job slot whereas a parallel job that has N components (tasks) uses N job slots which may span multiple hosts. A job slot can be used by at most one job. A job slot limit restricts the number of job slots that can be used at any one time. Each LSF Batch host, queue and user can have a job slot limit. Table 2 gives the combinations for which job slot limits can be configured, along with the parameter used to configure the corresponding limit.
| User (in lsb.users) | Host (in lsb.hosts) | Queue (in lsb.queues) | |
| Total | MAX_JOBS | MXJ | QJOB_LIMIT |
| Per user | JL/U | UJOB_LIMIT | |
| Per processor | JL/P | PJOB_LIMIT | |
| Per host | HJOB_LIMIT |
Job slot limits are used by queues in deciding whether a particular job belonging to a particular user should be started on a specific host. Depending on whether or not preemptive scheduling policy has been configured for individual queues, each queue can have a different way of counting jobs toward job slot limits. Below is how jobs use job slots from a queue's point of view:
This means that slots taken by suspended jobs are not counted toward the job slot limits in User and Host columns of Table 2.
The resulting counters are then used by this queue against various job slot limits during the scheduling of new jobs. Queues that can preempt others are more aggressive in scheduling jobs to hosts because a host appearing as full by a non-urgent queue would appear as not full from an urgent queue's point of view. See 'Preemptive and Preemptable' for the concept of preemptive scheduling.
Note
Although high priority preemptive queues neglect running jobs from low priority preemptable queues in checking job slot limits, LSF Batch will make sure that the total number of running jobs from a queue, a user, or on a host will not exceed the configured job slot limits in lsb.queues, lsb.users, and lsb.hosts. This is done by preempting (usually suspending) running jobs that can be preempted should the execution of a preemptive job cause the violation of the configured job slot limits.
Jobs are normally queued on a first-come, first-served basis. It is possible for some users to abuse the system by submitting a large number of jobs; jobs from other users must wait in the queue until these jobs complete. One way to prevent this is to use user job slot limits.
User job slot limits controls the number of job slots that can be used at once by a specific user or group of users. The definition of a job slot usage is dependent on queue's policy, as described in 'Job Slot Limits'.
A user can submit unlimited number of jobs to LSF Batch system, but the system will only schedule this user's jobs up to his/her job slot limits. The system will not schedule further jobs for the user until some of the scheduled jobs free up the used job slots. User job slot limits come in different forms.
Each user or group of users can be assigned a system wide job slot limit using the MAX_JOBS parameter in the lsb.users file.
Each user and user group can also be assigned a per-processor job slot limit using the JL/P parameter in the lsb.users file. For hosts that can run more than one LSF Batch job per processor, this prevents a user or group from using all the available job slots on the host.
User job slot limits are configured in the User section of the lsb.users file. See 'The lsb.users File'.
It is frequently useful to limit the maximum number of jobs that can be run on a host to prevent a host from being over-loaded with too many jobs and to maximize the throughput of a machine. Each host can be restricted to run a limited number of jobs at one time using the MXJ parameter in the Host section of the lsb.hosts file.
Each host can also restrict the number of jobs from each user allowed to run on the host, using the JL/U parameter in the lsb.hosts file. This limit is similar to the JL/P parameter in the lsb.users file. The JL/U parameter is configured for a particular host, and applies to all users on that host. The JL/P parameter is configured for a particular user, and applies to all hosts.
When a queue finds a host reaching one of its job slot limits, it will not start more jobs to this host until one or more job slots on the host are freed. The definition of a job slot usage is described in 'Job Slot Limits'.
For preemptive queues, if lower priority jobs are running on a host that has reached one of its job slot limits, LSF Batch will suspend one of these jobs to enable dispatch or resumption of a higher priority job.
Host job slot limits are configured in the Host section of the lsb.hosts file, which is described in 'The lsb.hosts File'.
The QJOB_LIMIT parameter in the lsb.queues file controls the number of job slots a queue can use at any time. This parameter can be used to prevent a single queue from using all the processing resources in the cluster. For example, a high priority queue could have a QJOB_LIMIT set so that a few hosts remain available to run lower priority jobs.
Each queue can have a limit on the number of job slots a single user is allowed to use in that queue at one time. This limit prevents a single user from filling a queue with jobs and delaying other users' jobs. For example, each user could be limited to use one job slot at a time in a high priority queue to discourage overuse of the high priority queue.
The per-user job slot limit of a queue is configured with the UJOB_LIMIT parameter in the lsb.queues file.
Each queue can also have a limit on the number of jobs dispatched from the queue to a single processor, configured using the PJOB_LIMIT parameter in the lsb.queues file. This limit restricts the number of jobs a particular queue sends to any one host, while still allowing jobs from other queues to be dispatched to that host.
The PJOB_LIMIT parameter applies to each processor on a host. This allows the same limit to apply for both uniprocessor and multiprocessor hosts, without leaving multiprocessors underused.
A queue can limit the number of job slots available to jobs that are sent to the same host regardless of the number of processors the host has. This is set using the HJOB_LIMIT parameter in the lsb.queues file. If all of the job slots of a host have been taken or reserved by the jobs in this queue, no more jobs in this queue can be started on that host until some of the slots are released.
A queue's job slot limit per host does not prevent jobs from other queues from being dispatched to that host. For example, a low priority queue could be restricted to starting one job per processor. Higher priority queues would still be allowed to start other jobs on that host. By setting a low suspending threshold on the low priority queue, the low priority job can be forced to suspend when the high priority job starts.
Queue job slot limits are configured in the Queue sections of the lsb.queues file, which is described in 'The lsb.queues File'.
Jobs submitted through the LSF Batch system will have the resources they use monitored while they are running. This information is used to enforce job-level resource limits as well as to improve the fairshare scheduling to consider the current cpu time used by a job.
Resource limits supported by LSF Batch are described in 'Resource Limits'.
Job-level resource usage is collected through a special process called PIM (Process Information Manager). PIM is managed internally by LSF. The information collected by PIM includes:
The -l option of the bjobs command displays the current resource usage of the job. The usage information is sampled by PIM every 30 seconds and collected by the sbatchd at a maximum frequency of every SBD_SLEEP_TIME (configured in the lsb.params file) and sent to the mbatchd. The update is done only if the value for the CPU time, resident memory usage, or virtual memory usage has changed by more than 10 percent from the previous update or if a new process or process group has been created.
Fairshare scheduling is an alternative to the default first-come, first-served scheduling. Fairshare scheduling divides the processing power of the LSF cluster among users and groups to provide fair access to resources for all the jobs in a queue. LSF allows fairshare policies to be defined at the queue level so that different queues may have different sharing policies. The fairshare policy of a queue applies to all hosts used by the queue.
Fairshare scheduling at the level of queues and host partitions (see below) are mutually exclusive.
For more information about how fairshare scheduling works and how to configure a fairshare queue, see 'Controlling Fairshare' and 'Queue Level Fairshare'.
Host partition provides fairshare policy at the host level. Unlike queue-level fairshare as described above, a host partition provides fairshare of resources on a group of hosts and it applies to all queues that use hosts in the host partition.
Fairshare scheduling at the level of queues and host partitions are mutually exclusive.
For more information about how fairshare works and how they can be used to create specific scheduling policies, see 'Controlling Fairshare' and 'Host Partitions'.
Preemptive scheduling allows LSF administrators to configure job queues such that a high priority job can preempt a low priority running job by suspending the low priority job. This is useful to ensure that long-running low priority jobs do not hold resources while high priority jobs are waiting for a job slot or job slots.
For more information about how preemptive scheduling works and how to configure a preemptive or preemptable queue, see 'Preemption Scheduling'.
Exclusive scheduling makes it possible to run exclusive jobs on a host. A job only runs exclusively if it is submitted to an exclusive queue, and the job is submitted with the bsub -x option. An exclusive job runs by itself on a host --- it is dispatched only to a host with no other batch jobs running, and LSF does not send any other jobs to the host until the exclusive job completes.
For more information about how exclusive scheduling works and how to configure an exclusive queue, see 'Exclusive Queue'.
Jobs running under LSF Batch may be suspended based on the load conditions on the execution host(s). Each host and each queue can be configured with a a set of suspending conditions. If the load conditions on an execution host exceed either the corresponding host or queue suspending conditions, one or more jobs running on that host will be suspended to reduce the load until the it falls below the suspending conditions.
LSF Batch provides different alternatives for configuring suspending conditions. Suspending conditions are configured at the host-level as suspending thresholds, whereas suspending conditions at the queue-level can be configured as either suspending thresholds, or use the STOP_COND parameter in the lsb.queues file, or both. See 'Host Section', 'Flexible Expressions for Queue Scheduling', and 'Load Thresholds' for details about configuration options for suspending conditions at host and queue levels.
The suspending conditions are displayed by the bhosts -l and bqueues -l commands. The thresholds which apply to a particular job are the more restrictive of the host and queue thresholds, and are displayed by the bjobs -l command.
LSF Batch checks the host load levels periodically. The period is defined by the SBD_SLEEP_TIME parameter in the lsb.params file. There is a time delay between when LSF Batch suspends a job and when the changes to host load are seen by the LIM. To allow time for load changes to take effect, LSF Batch suspends at most one job per SBD_SLEEP_TIME on each host.
Each turn, LSF Batch gets the load levels for that host. Then for each job running on the host, LSF Batch compares the load levels against the host suspending conditions and the queue suspending conditions for the queue that job was submitted to. If any suspending condition at either the corresponding host or queue level is satisfied as a result of increased load, the job is suspended.
Jobs from the lowest priority queue are checked first. If two jobs are running on a host and the host is too busy, the lower priority job is suspended and the higher priority job is allowed to continue. If the load levels are still too high on the next turn, the higher priority job is also suspended.
Note that a job is only suspended if the load levels are too high for that particular job's suspending conditions. It is possible, though not desirable, to configure LSF Batch so that a low priority queue has very loose suspending conditions. In this case a job from a higher priority queue may be suspended first, because the load levels are not yet too high for the low priority queue.
In addition to excessive load, jobs from a queue are also suspended if all the run windows of the queue close. The jobs are resumed when the next run window of the queue opens. For example, a night queue might be configured to run jobs between 7 p.m. and 8 a.m. If a job is still running in the morning, it is suspended, and is resumed around 7 p.m. of that day.
In contrast, when the dispatch windows of a queue or host close, jobs from that queue or running on that host keep running. The dispatch windows just control job dispatching.
Each host and queue can be configured so that suspended checkpointable or rerunable jobs are automatically migrated to another host. See 'Checkpointing and Migration'.
Two special cases affect job suspension. Both special cases are intended to prevent batch jobs from suspending themselves because of their own load. If a batch job is suspended because of its own load, the load drops as soon as the job is suspended. When the load goes back within the thresholds, the job is resumed until it causes itself to be suspended again.
When only one batch job is running on a host, the batch job is not suspended for any reason except that the host is not idle (the it interactive idle time load index is less than one minute). This means that once a job is started on a host, at least one job continues to run unless there is an interactive user on the host. Once the job is suspended it is not resumed until all the scheduling conditions are met, so it should not interfere with the interactive user.
The other case applies only for the pg (paging rate) load index. A large batch job often causes a high paging rate. Interactive response is strongly affected by paging, so it is desirable to suspend batch jobs that cause paging when the host has interactive users. The PG_SUSP_IT parameter in the lsb.params file controls this behaviour. If the host has been idle for more than PG_SUSP_IT minutes, the pg load index is not checked against the suspending threshold.
Jobs are suspended to prevent overloading hosts, to prevent batch jobs from interfering with interactive use, or to allow a more urgent job to run. When the host is no longer overloaded, suspended jobs should continue running.
LSF Batch uses queue-level and host-level scheduling thresholds as described in 'Host Load Levels' to decide whether a suspended job should be resumed. At the queue level, LSF Batch also uses the RESUME_COND parameter in the lsb.queues file. Unlike suspending conditions, all the resuming conditions must be satisfied for a job to get resumed.
If there are any suspended jobs on a host, LSF Batch checks the load levels in each turn. If the load levels are within the scheduling thresholds of both queue level and host levels, and the resume condition RESUME_COND configured at the queue level is satisfied, the job is resumed.
Jobs from higher priority queues are checked first. Only one job is resumed in each turn to prevent overloading the host again.
The scheduling thresholds that control when a job is resumed are displayed by the bjobs -l command.
A job may also be suspended by its owner or the LSF administrator with the bstop or bkill -TSTP commands. These jobs are considered user-suspended (displayed by bjobs as USUSP).
When the user restarts the job with the bresume or bkill -CONT commands, the job is not started immediately to prevent overloading. Instead, the job is changed from USUSP to SSUSP (suspended by the system). The SSUSP job is resumed when the host load levels are within the scheduling thresholds for that job, exactly as for jobs suspended because of high load.
If a user suspends a high priority job from a non-preemptive queue, the load may become low enough for LSF Batch to start a lower priority job in its place. The load created by the low priority job can prevent the high priority job from resuming. This can be avoided by configuring preemptive queues (see 'Preemptive and Preemptable').
A batch job can be submitted in interactive mode such that all input and output are through the terminal from which the bsub command is issued. The principal advantage of running in an interactive job through the LSF Batch system is that it takes advantage of the batch scheduling policy and host selection features for resource intensive jobs. Additionally, all statistics related to the job are recorded in the lsb.acct file to allow a common accounting system for both interactive and non-interactive jobs.
An interactive batch job is submitted by specifying the -I option to the bsub command. An interactive batch job is scheduled with the same policy as for all other jobs in a queue. This means an interactive job can wait for a long time before it gets dispatched. If fast response time is required, interactive jobs should be submitted to high priority queues with loose scheduling constraints.
Each batch job can be submitted with optional pre- and post-execution commands.
If a pre-execution command is specified, the job is held in the queue until the specified pre-execution command returns a successful exit status (zero). While the job is pending, other jobs may go ahead of the waiting job.
If a post-execution command is specified, then the command is run after the job is finished.
Pre- and post-execution commands are arbitrary command lines.
Pre-execution commands can be used to support job starting decisions which cannot be configured directly in LSF Batch.
Post-execution commands are typically used to cleanup some state left by the pre-execution and the job execution.
LSF Batch supports both job level and queue level pre-execution. Post-execution is only supported at the queue level.
See 'Queue-Level Pre-/Post-Execution Commands' for more information about queue-level pre/post-execution commands, and the chapter 'Submitting Batch Jobs'of the LSF User's Guide for more information about the job-level pre-execution commands.
Batch jobs can be checkpointed and migrated to other hosts of the same type. LSF supports three forms of checkpointing:
Kernel level checkpointing is currently supported on ConvexOS and on Cray Unicos systems. LSF Batch provides a uniform checkpointing protocol to support checkpointing at all levels for all platforms by providing the commands echkpnt and erestart2.
Details of checkpointing are described in the chapter 'Checkpointing and Migration' of the LSF User's Guide.
Checkpointable jobs and rerunable jobs can be migrated to another host for execution if the current host is too busy or the host is going to be shut down. A rerunable job is a job that is submitted with the bsub -r option and can be correctly rerun from the beginning. Jobs can be moved from one host to another, as long as both hosts are binary compatible and run the same version of the operating system.
The job's owner or the LSF administrator can use the bmig command to migrate jobs. If the job is checkpointable, the bmig command first checkpoints it. Then LSF kills the running or suspended job, and restarts or reruns the job on another host if one is available. If LSF is unable to rerun or restart the job due to a system or network reason, the job reverts to PEND status and is requeued with a higher priority than any submitted job, so it is rerun or restarted before other queued jobs are dispatched.
LSF Batch needs to control jobs dispatched to a host to enforce scheduling policies or in response to user requests. The principal actions that the system performs on a job include suspending, resuming and terminating it. By default, the actions are carried out by sending the signal SIGSTOP for suspending a job, SIGCONT for resuming a job and SIGKILL for terminating a job.
Sometimes you may want to override the default actions. For example, instead of suspending a job, you may want to kill or checkpoint a job. The default job control actions can be overridden by defining the JOB_CONTROLS parameter in your queue configuration. Each queue can have its separate job control actions. See 'Job Starter' for more details.
When a job is dispatched, the system assumes that the resources that the job consumes will be reflected in the load information. However, many jobs often do not consume the resources they require when they first start. Instead, they will typically use the resources over a period of time. For example a job requiring 100 megabytes of swap is dispatched to a host having 150 megabytes of available swap. The job starts off initially allocating 5 megabytes and gradually increase the amount consumed to 100 megabytes over a period of 30 minutes. During this period, another job requiring more than 50 megabytes of swap should not be started on the same host to avoid over-committing the resource.
Resources can be reserved to prevent over commitment of resources by LSF Batch. Resource reservation requirements can be specified as part of the resource requirements when submitting a job, or can be configured into the queue level resource requirements. See 'Queue-Level Resource Reservation' for details about configuring resource reservation at the queue level. For descriptions about specifying resource reservation with job submission, see the LSF User's Guide, or the LSF JobScheduler User's Guide.
When parallel jobs have to compete with sequential jobs for resources, a common situation is that parallel jobs will find it very difficult to get enough processors to run. This is because a parallel job needs to collect more than one job slot before it can be dispatched. There may not be enough job slots at any one instant to satisfy a large parallel job, but there may be enough to allow a sequential job to be started. This may cause parallel jobs to wait forever, if there are enough sequential jobs.
Processor reservation of the LSF Batch solves this problem by reserving processors for parallel jobs. When a parallel job cannot be dispatched because there are not enough job slots to satisfy its minimum processor requirements, the currently available slots will be reserved for the job. These reserved job slots are accumulated until there are enough available to start the job. When a slot is reserved for a job it is unavailable to any other job. To avoid deadlock situations, the period of reservation needs to be configured so that the parallel job will give up the reserved job slots if it still cannot run after the reservation period. See 'Processor Reservation for Parallel Jobs' for details about the reservation period configuration.
When LSF Batch runs a job, it attempts to run the job in the directory where the bsub command was invoked. If the execution directory is under the user's home directory, sbatchd looks for the path relative to the user's home directory. This handles some common configurations, such as cross-mounting users' home directories with the /net automount option.
If the directory is not available on the execution host, the job is run in /tmp. Any files created by the batch job, including the standard output and error files created by the -o and -e options to the bsub command, are left on the execution host.
LSF provides support for moving user data from the submission host to the execution host before executing a batch job, and from the execution host back to the submitting host after the job completes. The file operations are specified with the -f option to bsub.
The LSF Batch remote file access mechanism uses lsrcp(1) to process the file transfer. lsrcp first tries to connect to the RES daemon on the submission host to handle the file transfer. If lsrcp cannot contact the RES on the submission host, it attempts to use rcp to copy the file. You must set up the /etc/hosts.equiv or $HOME/.rhosts file in order to use rcp. See the rcp(1) and rsh(1) manual pages for more information on using rcp.
A site may replace lsrcp with its own file transfer mechanism as long as it supports the same syntax as lsrcp(1). This may be done to take advantage of a faster interconnection network or to overcome limitations with the existing lsrcp. sbatchd looks for the lsrcp executable in the LSF_BINDIR directory as specified in the lsf.conf file.
For a complete description of the LSF remote file access facilities, see the bsub(1) manual page and the LSF User's Guide.
A networked computing environment is vulnerable to any failure or temporary conditions in network services or processor resources. For example, you may get NFS stale handle errors, disk full errors, process table full errors, or network connectivity problems. In addition, your application may also be subject to external conditions such as a software license problem, or an occasional failure due to a bug in your application.
Such errors are temporary and probably will happen at one time but not the other, or on one host but not another. You may be upset to learn all your jobs exited due to temporary errors and you did not know about it until 12 hours later.
LSF Batch provides a way to automatically recover from temporary errors. You can configure certain exit values such that in case a job exits with one of the values, the job will be automatically requeued as if it had not been dispatched yet. This job will then be retried later. It is also possible for you to configure your queue such that a requeued job will not be scheduled to hosts on which the job had previously failed to run. See 'Automatic Job Requeue' and 'Exclusive Job Requeue' for details.
Administrators can write external submission and execution time executables to perform additional site-specific actions on jobs. These executables are called esub and eexec and they must reside in LSF_SERVERDIR (defined in the lsf.conf file). When a job is submitted, esub is executed if it is found in LSF_SERVERDIR. On the execution host, eexec is run at job start-up and completion time, and when checkpointing is initiated. The environment variable, LS_EXEC_T, is set to START, END, and CHKPNT, respectively, to indicate when eexec is invoked. If esub needs to pass some data to eexec, esub can write the data to its standard output; eexec can read the data from its standard input. Thus, LSF is effectively implementing the pipe in esub | eexec.
eexec is executed as the user after the job's environment variables have been set. If you need to run eexec as a different user, such as root, you must properly define LSF_EEXEC_USER in the file /etc/lsf.sudoers (see 'The lsf.sudoers File' for details). The parent job process waits for eexec to complete before proceeding; thus, eexec is expected to complete. The environment variable, LS_JOBPID, stores the process ID of the process that invoked eexec. If eexec is intended to monitor the execution of the job, eexec must fork a child and then have the parent eexec process exit. The eexec child should periodically test that the job process is still alive using the LS_JOBPID variable.
Interactive remote execution also runs these external executables if they are found in LSF_SERVERDIR. For example, lsrun invokes esub, and the RES runs eexec before starting the task. esub is invoked at the time of the ls_connect(3) call, and the RES invokes eexec each time a remote task is executed. Unlike LSF Batch, the RES runs eexec only at task startup time.
The esub/eexec facility is currently used for processing DCE credentials and AFS tokens (see 'Installing on AFS' and 'Installing on DCE/DFS').
This feature applies to LSF JobScheduler only.
LSF has an open system architecture to allow each site to customize the behaviour of the system. External events are site specific conditions that can be used to trigger job scheduling actions. Examples of external events are data arrival, tape silo status, and exceptional conditions. External events are collected by the External Event Daemon (eeventd). The eeventd runs on the same host as the mbatchd and collects site specific events that LSF JobScheduler will use to trigger the scheduling of jobs. LSF JobScheduler comes with a default eeventd that monitors file events. A user site can easily add more event functions to it to monitor more events.
For more details see 'External Event Management'.
LSF Base contains a Load Information Manager (LIM) that collects 11 built-in load indices that reflect the load situations of CPU, memory, disk space, I/O, interactive activities on individual hosts.
While built-in load indices may be sufficient for most user sites, there are always user sites with special workload or resource dependencies that require additional load indices. LSF's open system architecture allows users to write an External Load Information Manager (ELIM) that gathers additional load information a site needs. This ELIM can then be plugged into LIM so that they appear as a single LIM to the users. External load indices are used in exactly the same way as built-in load indices in various scheduling or host selection policies.
ELIM can be as simple as a small script, or as complicated as a sophisticated C program. A well defined protocol allows the ELIM to talk to LIM. See 'Changing LIM Configuration' for details about writing and configuring an ELIM.
2. echkpnt and erestart are located in LSF_SERVERDIR (defined in the lsf.conf file). Otherwise, the location is defined via the environment variable LSF_ECHKPNTDIR.
Copyright © 1994-1997 Platform Computing Corporation.
All rights reserved.